
DevLog @ 2025.08.26
お久しぶりです、AIRI メンテナーの一人、@LemonNeko です。ああ、LLM のようにこうやって始めるのには少し飽きてきました。
前回の DevLog で、Factorio Learning Environment の論文を軽く見て、airi-factorio をどのように改善する予定かについて簡単に話しました。しかし...今日皆さんと共有したいのはそれではなく、純粋な視覚方向の進捗状況についてです。
今年の6月、@nekomeowww がほぼリアルタイムの VLM Playground HuggingFace Spaces をリリースしました。これは非常にクールだと感じたので、まずは単純なリアルタイム画像認識(当時は物体検出と画像認識を混同していました)を試して、何らかの方法で AI に意思決定を任せ、最終的に何らかの方法でアクションを出力してゲームに実行させることにしました。
まずは成果をお見せします:
動画では、Web ページ内で VNC に接続して Factorio をプレイしています。右側は物体検出の結果で、ほぼリアルタイムです。HuggingFace Space にもデプロイしたので、ぜひ遊んでみてください。
さて、どうやって実現したのでしょうか?
Factorio クライアントを Docker に入れる
AI にゲーム画面を見せるためには、Factorio がウィンドウサイズや位置などの影響を受けない制御可能な環境で実行されるようにする必要があります。同時に、この環境がすぐに使えるものであることも望ましいです。そこで、Factorio を Docker に入れることにしました。
Factorio 公式は Docker イメージ を提供していますが、それは純粋なサーバー用です。AI に画面を見せてゲームを制御させるにはクライアントが必要ですが、既製の Docker イメージは見つかりませんでした(Factorio のライセンス契約では、このようにクライアントを配布することは許可されていません)。自分でパッケージ化する必要があります(それでも、パッケージ化したクライアントイメージを配布することはできず、Dockerfile を共有することしかできません)。
では、Factorio クライアントという象を Docker という冷蔵庫に入れるには、いくつのステップが必要でしょうか?
- Factorio クライアントをダウンロード:もちろん、これが主役です。
- 仮想ディスプレイを準備:GUI アプリケーションには画面を表示するためのディスプレイが必要です。
- VNC サービスを準備:仮想ディスプレイの内容を読み取り、外部の VNC クライアントに画面を送信し、同時にユーザー入力をゲームに送信できます。
何か忘れていませんか?ああ、音声?音声なんてありません。現在の AI はまだ音を聞くことができないので、とりあえず無視します。
Factorio クライアントのダウンロード
Factorio 公式サイトから直接ダウンロードをクリックできますが、手動でログインする必要があり、自動化プロセスの構築には不便です。そこで、ダウンロードスクリプト factorio-dl を見つけました。これは非常に複雑なシェルスクリプトで、ユーザー名、パスワード、ダウンロードするバージョンを指定すると、システムアーキテクチャに応じて対応するクライアントを自動的にダウンロードします。
仮想ディスプレイの準備
このステップは少し複雑ですが、デスクトップ環境全体をインストールするほど複雑ではありません。私もこの時初めて知ったのですが、GUI プログラムにはデスクトップ環境やウィンドウマネージャは必要なく、最も単純な X 環境とディスプレイサーバーがあれば十分です。
非常に簡単です:
sudo apt install -y xvfb x11-apps mesa-utilsここで:
xvfbは仮想フレームバッファおよび X サーバーです。x11-appsはいくつかの X 関連ツールで、インストール時に X 環境も同時にインストールされます。mesa-utilsはいくつかの Mesa 関連ツールです。Mesa は OpenGL のソフトウェア実装であり、OpenGL プログラムのテストとデバッグに役立つツールを提供します。
VNC サービスの準備
VNC は Virtual Network Computing の略で、リモートデスクトッププロトコルです。これを使用すると、まるでそのコンピュータの前に座っているかのように、別のコンピュータをリモート制御できます。
sudo apt install -y x11vncこれらがあれば、Docker 内で Factorio クライアントを実行し、VNC で制御できます。
しかし、これだけでは不十分です。私の目標は、ブラウザでプレイしながらリアルタイムで物体検出の推論を行うことです。しかし、ブラウザでは HTTP プロトコルしか使用できないため、websockify などのツールを使用して VNC プロトコルを HTTP プロトコルに変換する必要があります。同時に、デバッグを容易にするために、VNC 画面を表示する Web インターフェースも必要なので、novnc もインストールする必要があります。
sudo apt install -y websockify novncこれで Docker イメージの準備が整いました。完全な Dockerfile と使用説明はこちらで確認できます。
物体検出モデルのトレーニング
迅速に検証するために、YOLO11n の事前トレーニング済みモデルをベースにして、物体検出モデルをトレーニングしました。
データセットの準備
私は次のようにデータセットを収集しました:
surface.create_entity関数を使用して、シーン内のランダムな位置にマシンとマシンの選択ボックス(selection_box)のサイズと位置を配置します。game.take_screenshotを使用して、さまざまなズーム比率と照明条件(daytime)でスクリーンショットを撮ります。- 選択ボックスに基づいて注釈データを生成し、
helpers.write_fileを使用してファイルに保存します。
私の収集スクリプトはここにあります。typescript-to-lua を使用して TypeScript を Lua にコンパイルし、RCON を使用して Factorio に渡して実行します。
スクリプトでは、3 つのモデルの組立機とベルトコンベアを収集しました。各マシンについて 20 枚の画像、各画像は 1280x1280 の解像度で、UI は含まれていません。
ああ、それと、収集スクリプトをより適切にデバッグするために、VSCode プラグインを開発しました。これは CodeLens アクションを提供し、ワンクリックでスクリプトをコンパイルして実行できます。
画像と注釈データが収集されたら、YOLO 公式の形式に従ってデータセットを整理し、Ultralytics Hub にアップロードして効果を確認できます:
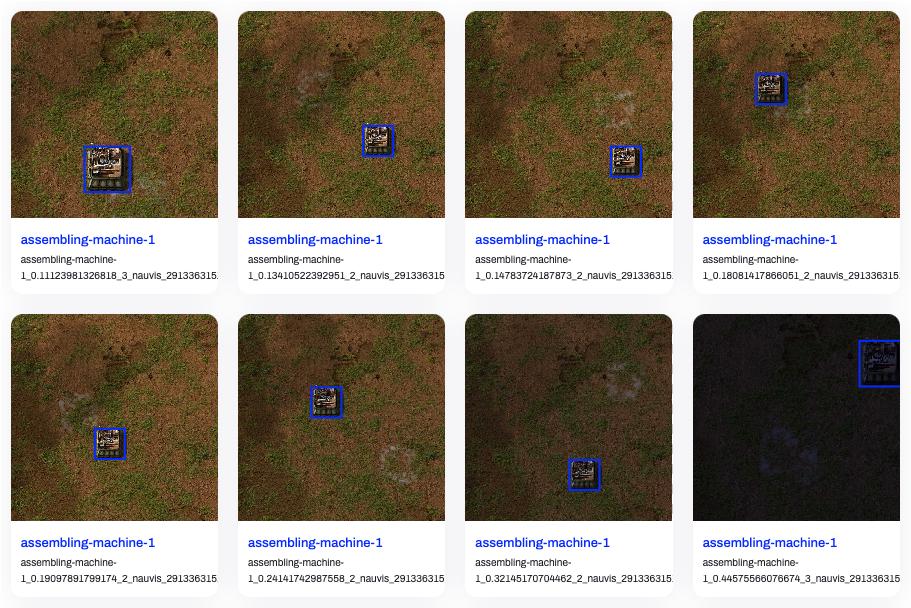
悪くないでしょう?では、トレーニングを始めましょう!
モデルのトレーニング
初心者なので、Get Started から始めて、次の数行のコードをコピーしました:
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
model.train(data="./dataset/detect.yaml", epochs=100, imgsz=640, device="mps")
model.export(format="onnx")640x640 の解像度で、MPS デバイス(macOS では MPS デバイスを使用するとパフォーマンスが向上します)を使用して、100 エポックトレーニングしました。各エポックには 5 つのバッチがあり、約 70 エポックで最良の結果が得られました。ONNX モデルをエクスポートしました。トレーニングには約 8 分かかり、モデルサイズは約 10MB でした。
データセット、トレーニングコード、およびエクスポートされた ONNX モデルはここで見ることができます。
推論の実行
これで、上記の 2 つの部品を組み立てることができます。私は以下を使用しました:
@novnc/novnc:ブラウザに VNC 画面を表示し、同時にキャンバスからデータを取り出してモデルに供給します。onnxruntime-web:ブラウザで推論を実行します。WebGPU のサポートを提供しており、GPU のパフォーマンスを利用できます。
最初は推論速度が非常に遅く、約 400ms かかり、UI がフリーズして VNC さえまともに表示できませんでした。私は WebWorker の使用方法を一時的に学び、推論と表示を分離することでこの問題を解決しました。そして、実際には WebGPU を有効にしていなかったことに気づいたので、速度はまだ遅いままです。
ort.InferenceSession.create(model, { executionProviders: ['webgpu', 'wasm'] })WebGPU と WASM の 2 つの実行モードを使用できるように明確に記述する必要があります。これにより、WebGPU が利用できない場合に自動的に WASM 実行に切り替わります。
WebGPU を有効にした後、推論速度は約 80ms に向上しましたが、まだ遅いと感じました。しかし、これ以上どう最適化すればよいかわかりませんでした。その時、Cursor が言いました。「ピクセルカラー値を正規化するときに、常に 255 で割っていますね。最初に 1/255 を計算してから、その値を直接掛けるべきです。そうすれば割り算を回避できます」。
ん?待って、割り算は掛け算より遅いのですか?やはりスキップしたコンピュータサイエンスの授業は補う必要があります。
Cursor の提案に従ってコードを変更したところ、推論速度は約 20ms に向上し、体験は非常に良くなりました。
モデル出力の処理部分をスキップしたので、次にモデル出力を処理する方法を見てみましょう。
モデル出力の処理
モデルは 84000 個の要素を持つ配列と、dims が [1, 10, 8400] の配列を出力します。これは、84000 個の要素が 10 個のグループに分かれており、各グループにはバウンディングボックスの中心 x および y 座標、バウンディングボックスの幅と高さ、6 つのクラスそれぞれの信頼度があり、合計 8400 組の結果があることを意味します。
信頼度 0.6 をしきい値として信頼度の低いバウンディングボックスを除外した後、重なり合うバウンディングボックスを除外するために NMS 手段として IOU を使用する必要があります。
IOU と NMS については、この記事を参照してください。簡単に言えば、2 つのボックスの面積を足し、それらの重なり合う面積を引いて実際の占有面積を取得し、重なり合う面積を実際の占有面積で割って IOU を取得します。
私は非常に単純な NMS 実装を使用しました。すべてのバウンディングボックスを信頼度でソートし、高い順に走査します。バウンディングボックスの IOU が 0.7 より大きい場合、それらは同じ物体であると見なし、除外します。
function nms(boxes: Box[], iouThreshold: number): Box[] {
// 1. Filter by confidence and sort in descending order
const candidates = boxes
.filter(box => box.confidence > 0.6)
.sort((a, b) => b.confidence - a.confidence)
const result: Box[] = []
while (candidates.length > 0) {
// 2. Pick the box with the highest confidence
const bestCandidate = candidates.shift()!
result.push(bestCandidate)
// 3. Compare with remaining boxes and remove ones with high IOU
for (let i = candidates.length - 1; i >= 0; i--) {
// The iou() function needs to be implemented separately, as described in the article.
if (iou(bestCandidate, candidates[i]) > iouThreshold) {
candidates.splice(i, 1)
}
}
}
return result
}Playground 全体のソースコードはここで見ることができます。
また、以下の可視化コンポーネントで IOU と NMS の効果を体験することもできます。タグをドラッグしてボックスの位置を変更してください:
box1y1: 100
box1y2: 300
box2y1: 150
box2y2: 350
発見された問題
このように実践してみて、いくつか問題を発見しました:
- 正方形でない画像を認識できない:正方形でない画像に遭遇すると、モデルが出力するすべての結果の信頼度が非常に低くなり、0 になることさえあります。
- モデルはレベル 1 の組立機とレベル 2 の組立機を区別できますが、チェストなどの正方形の物体も組立機として認識してしまいます。
- 実際のゲームでは、マシンのテクスチャに電力、現在のレシピ、使用中のプラグインなどの状態アイコンが重なることが多く、これらのアイコンがモデルの認識を妨げます。
最後に
ここまでが今月の私の成果です。収穫は多かったですね。私の助けになってくれた @nekomeowww、@dsh0416、makito に感謝します。次はモデルのパフォーマンスを向上させる方法を考え、何らかの方法で AI にゲームを制御させるつもりです。